Salesforce - из э малтитэнант платформ, а это, кроме прочего, означает, что производительность и эффективность SOQL запросов является крайне важной частью работы с ней.
Следует заметить, что когда речь идёт о запросах к базе данных, имеются в виду не только SOQL запросы в апекс коде, но и работа репортов и list views. Ведь если, например, репорт составлен не избирательно (без фильтров или с малым количеством фильтров), а записей много (больше 100000),
каждое его обновление будет занимать довольно длительное время. Поэтому запросы к базе следует делать selective. В репортах и list views с помощью фильтров, в SOQL-запросах - с помощью WHERE условий.
Однако, даже если запрос должен вернуть небольшое количество записей, это ещё не означает, что он быстро их найдёт. Допустим, запрос должен вернуть одну запись. Для этого ему нужно последовательно перебрать всю таблицу
и найти её. Всё ещё не очень быстро, верно? И тут на арене появляются индексы.
Стандартное индексирование или поля, которые индексируются по умолчанию:
- RecordTypeId
- Division
- CreatedDate
- Systemmodstamp (LastModifiedDate)
- Name
- Email (у контактов и лидов)
- Foreign key связи (lookups и master-detail)
- Salesforce record ID, являющийся primary key для каждого объекта.
- External IDs
Кастомный индекс может быть добавлен для полей по обращению в Salesforce Customer Support.
Не могут быть индексированы такие типы полей:
- multi-select picklists
- text areas (long)
- text areas (rich)
- non-deterministic formula fields (которые обращаются к другим формулам, полям других объектов или используют динамические функции даты и времени, как TODAY() или NOW())
- encrypted text fields
Как это работает.
Для индексированного поля в базе данных на сервере Salesforce создаётся дополнительная таблица, которая содержит в себе копию данных из этого поля, информацию об их типе и ссылку на соответствующую строку в оригинальной таблице.
Смысл подобного подхода в том, что данные в этой дополнительной таблице упорядочены, что позволяет применить более эффективные алгоритмы поиска вместо того, чтобы перебирать все записи подряд. Тем не менее, индексированный поиск работает не всегда.
Он является достаточно ресурсо-затратным, ведь нужно не просто найти запись в таблице индексов, но и выбрать её из оригинальной таблицы. Обычно, в реляционных базах данных поиск по индексам применяется только тогда, когда
в выборку попадает меньше 30% строк из запрашиваемой таблицы, а если их больше, то он уже не имеет смысла.
Salesforce не стал исключением в этом плане. Для стандартных полей, которые индексированы изначально, индексы используются для выборок, которые содержат до 30% из первого миллиона записей, + 15% от остальных записей запрашиваемого объекта, но не более одного миллиона.
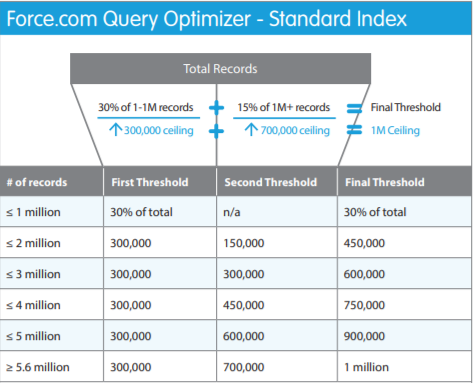
Для полей, которые индексированы кастомно, лимит составляет 10% от первого миллиона записей + 5% от остальных, но не более 333333 записей.
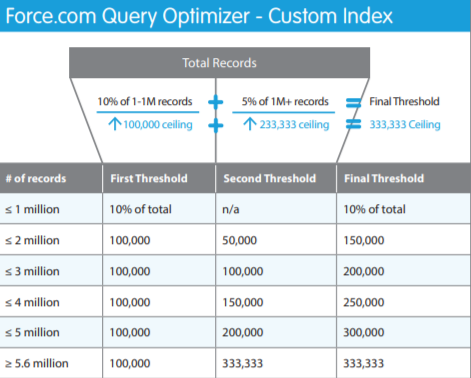
В случае, когда в выборку попадает большее количество записей, чем разрешено лимитами, запрос продолжает работать, но индексы не используются.
А ещё они не будут использоваться в случаях:
- когда в WHERE условии используются негативные операторы (!=, NOT LIKE, EXCLUDES);
- когда в WHERE условии присутствует сравнение текстовых полей операторами >, <, >=, <=;
- когда в WHERE условии используется символ “%” в начале строки (например, field__c LIKE “%string”)