Всем привет.
Давайте рассмотрим гипотетическую ситуацию, что к вам обратился клиент и просит разработать для него возможность считывания информации с изображений, загруженных в Salesforce.
Это могут быть сканкопии каких-либо документов, либо фотографии, данные из которых необходимо сохранить в текстовом виде (например паспорт или водительское удостоверение) и возможно, заполнить ими какую-то форму. Запросы могут быть разнообразными. Сегодня рассмотрим простейшую реализацию этой задачи.
Этот функционал можно реализовать с помощью сервисов платформы Einstein Vision API. Для этого необходимо создать учетную запись в Einstein Platform Services, создать ключ и сгенерировать токен для доступа.
Однако, сегодня я хотел бы рассмотреть сторонний сервис. Такой как GOOGLE CLOUD VISION API. Этот API позволяет разработчикам получить содержание изображения используя мощные модели машинного обучения, просто через REST API. Довольно мощная штука, с помощью которой мне даже удавалось распознать рукописный текст, написанный печатными буквами.
Итак:
-
для начала нам нужно создать пользователя на https://console.developers.google.com, либо воспользоваться любым существующим аккаунтом Gmail.
-
далее нужно создать проект в Google Console (можно воспользоваться этой ссылкой https://console.cloud.google.com/projectcreate).
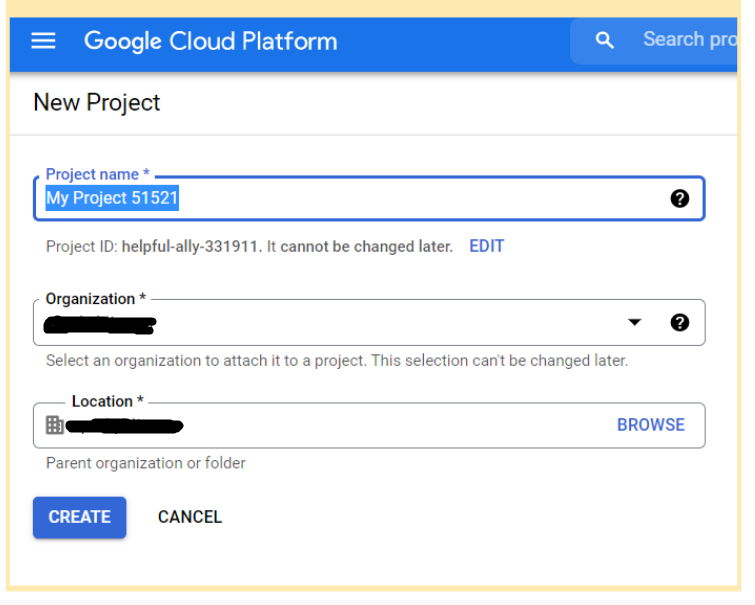
-
после этого вы попадете на страничку своего проекта, где необходимо провести несложные действия. Нужно перейти по этой ссылке https://console.developers.google.com/apis/library в библиотеку API и подключить Google Cloud Vision к вашему проекту.
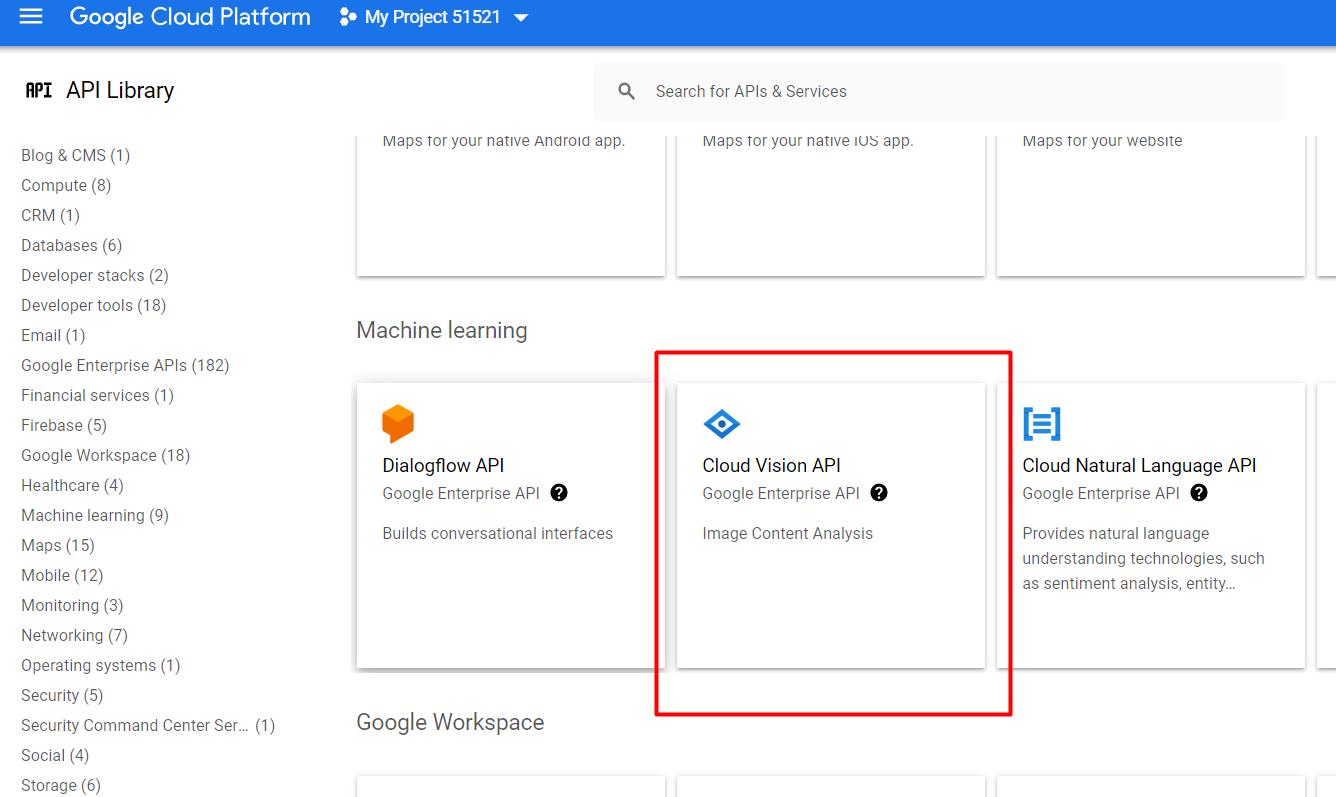

- далее необходимо создать ключ API:
- Выглядеть это будет примерно вот так:

- копируем ключик. Далее он нам пригодится.
- также необходимо не забыть добавить сайт https://vision.googleapis.com в список разрешенных сайтов в Salesforce.

Да, чуть не забыл. Google попросит вас подвязать банковскую карту, чтоб верифицировать, что вы настоящий пользователь. Это можно сделать в графе Billing в боковом меню. После подвязки карты с нее снимут 1$ и тут же положат его обратно. Без совершения этих действий ваши запросы обрабатываться не будут. За отправляемые запросы гугл деньги с меня не снимал 
Далее, необходимо написать Apex классы, в нашем случае ImageService, которые будут отправлять и получать информацию.
public class ImageService {
public static ImageResponse GetTextFromImage(blob data)
{
HttpRequest httpReq = new HttpRequest();
httpReq.setHeader('Content-Type','application/json; charset=utf-8');
httpReq.setMethod('POST');
httpReq.setEndpoint('https://vision.googleapis.com/v1/images:annotate?key=AIzaSyDwq************50rh3Nb4CZLhH5A'); - ключ который получили в гугл
httpReq.setTimeout(120000);
ImageRequest imageRequest = new ImageRequest();
ImageRequest.Image image = new ImageRequest.Image();
image.content = data;
ImageRequest.Feature feature = new ImageRequest.Feature();
feature.type ='TEXT_DETECTION';
ImageRequest.Request request = new ImageRequest.Request();
request.features = new List<ImageRequest.Feature>();
request.features.add(feature);
request.Image = image;
imageRequest.requests = new List<ImageRequest.Request>();
imageRequest.requests.add(request);
httpReq.setBody(JSON.serialize(imageRequest));
Http http = new Http();
HTTPResponse res = http.send(httpReq);
return ImageResponse.parse(res.getBody());
}
}
public class ImageRequest{
public List<Request> requests;
public class Request {
public Image image;
public List<Feature> features;
}
public class Image {
public blob content;
}
public class Feature {
public String type;
}
public static ImageRequest parse(String json){
return (ImageRequest) System.JSON.deserialize(json, ImageRequest.class);
}
}
public class ImageResponse {
public Responses[] responses;
public class Responses {
public TextAnnotation[] textAnnotations;
public FullTextAnnotation fullTextAnnotation;
}
public class TextAnnotation {
public String locale;
public String description;
public BoundingPoly boundingPoly;
}
public class BoundingPoly {
public Vertice[] vertices;
}
public class Vertice {
public Integer x;
public Integer y;
}
public class FullTextAnnotation {
public ImagePage[] pages;
public String text;
}
public class ImagePage {
public Property property;
public Integer width;
public Integer height;
public Block[] blocks;
}
public class Property {
public DetectedLanguage[] detectedLanguages;
}
public class DetectedLanguage {
public String languageCode;
}
public class Block {
public Property property;
public BoundingBox boundingBox;
public Paragraph[] paragraphs;
public String blockType;
}
public class BoundingBox {
public Vertice[] vertices;
}
public class Paragraph {
public Property property;
public BoundingBox boundingBox;
public Word[] words;
}
public class Word {
public Property property;
public BoundingBox boundingBox;
public Symbol[] symbols;
}
public class Symbol {
public Property property;
public BoundingBox boundingBox;
public String text;
}
public static ImageResponse parse(String json){
return (ImageResponse) System.JSON.deserialize(json, ImageResponse.class);
}
}
Информация об изображении передается в base64 кодировке и возвращается обратно в JSON формате.
Создадим кастомный объект с названием Info from file. На этом объекте создадим кастомное поле Image info (rich text), в которое и будем сохранять информацию с нашего изображения. Изображение в виде Attachments будем загружать в Account. Реализация дата-модели может быть абсолютно разной, в зависимости от потребностей бизнеса. В данном примере акцент сделан больше на сам момент использования стороннего сервиса и извлечение данных.
Для извлечения информации из полученного ответа давайте создадим Аура-компонент и контроллер для него.
public class ImageServiceController {
@auraenabled
public static ImageResponse GetTextFromImage(string record)
{
List<ContentDocumentLink> docs=[SELECT ContentDocumentId
FROM ContentDocumentLink
WHERE ContentDocument.FileType='jpg'
and LinkedEntityId =:record];
if(!docs.isempty())
{
List<ContentVersion> updateVersionList=new List<ContentVersion>();
for(ContentDocumentLink doc:docs)
{
List<ContentVersion> versions=[SELECT VersionData
FROM ContentVersion
WHERE Is_Extracted__c=false
and ContentDocumentId = :docs[0].ContentDocumentId
AND IsLatest = true];
if(versions.isempty()){
return null;
}
ContentVersion version=versions[0];
ImageResponse response=ImageService.GetTextFromImage(version.VersionData);
Info_from_file__c info = new Info_from_file__c();
info.Image_Info__c = response.responses[0].fullTextAnnotation.text;
insert info;
}
}
return null;
}
}
<aura:component controller="ImageServiceController" implements="lightning:isUrlAddressable,force:hasRecordId,force:appHostable,flexipage:availableForAllPageTypes,flexipage:availableForRecordHome,force:hasRecordId,forceCommunity:availableForAllPageTypes,force:lightningQuickAction" access="global" >
<aura:handler name="init" value="{!this}" action="{!c.extractImage}"/>
<aura:attribute name="recordId" type="Id" />
<aura:attribute name="status" type="string" />
<div class="slds-text-align_center">
{!v.status}
</div>
</aura:component>
({extractImage : function(cmp)
{var action = cmp.get("c.GetTextFromImage");
action.setParams({ record : cmp.get("v.recordId") });
action.setCallback(this, function(response) {
var state = response.getState();
if (state === "SUCCESS") {
cmp.set("v.status",'Text extracted from image.');
}
else if (state === "INCOMPLETE") {
cmp.set("v.status",'Incomplete');
}
else if (state === "ERROR") {
var errors = response.getError();
if (errors) {
if (errors[0] && errors[0].message) {
cmp.set("v.status","Error message: " + errors[0].message);
}
} else {
cmp.set("v.status",'Unknown error');
}
}
});
$A.enqueueAction(action);
}
})
Добавим компонент на страницу Account в виде Action. Назовем его Extract.

Теперь можно приступить к самому интересному — к тестированию. Найдем несколько изображений в интернете. Пусть это будет фото текста на украинском, например:

И водительское удостоверение Украины:

Создадим тестовый аккаунт. И загрузим в аттачменты наше фото текста.

Нажимаем Extract…
Видим через несколько секунд информационное окно, сообщающее нам об успешном завершении работы.
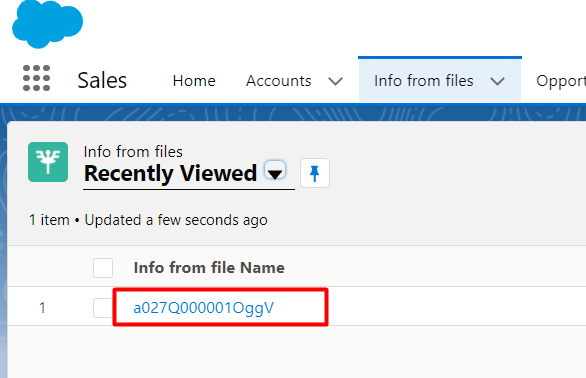
Переходим на вкладку с нашим кастомным объектом и видим, что создана запись.
Открываем ее и видим…
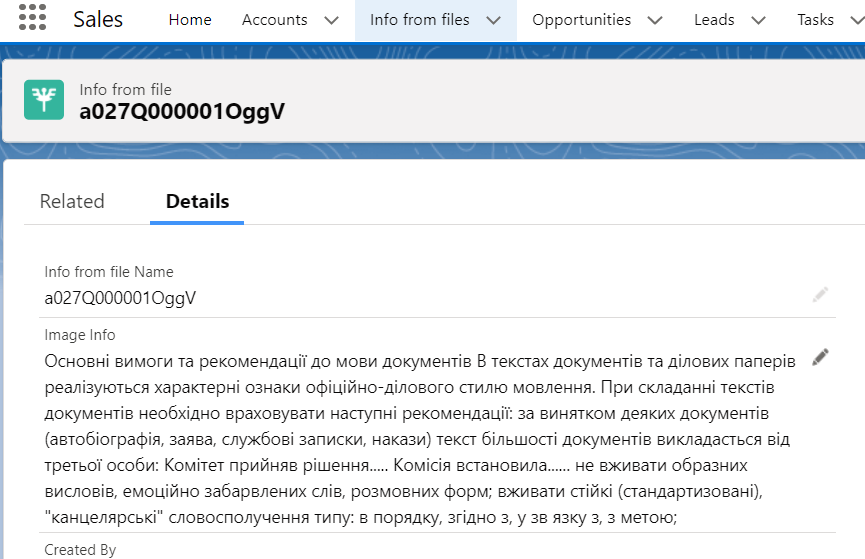
Как мы можем видеть, воспроизведенный текст соответствует фотографии, которую мы загрузили, с довольно высокой точностью. Это обьясняется хорошим качеством изображения и отсутствием постороннего «шума» на фото. Результат работы также можно увидеть в этом видео.
Теперь давайте посмотрим на результат преобразования водительского удостоверения:
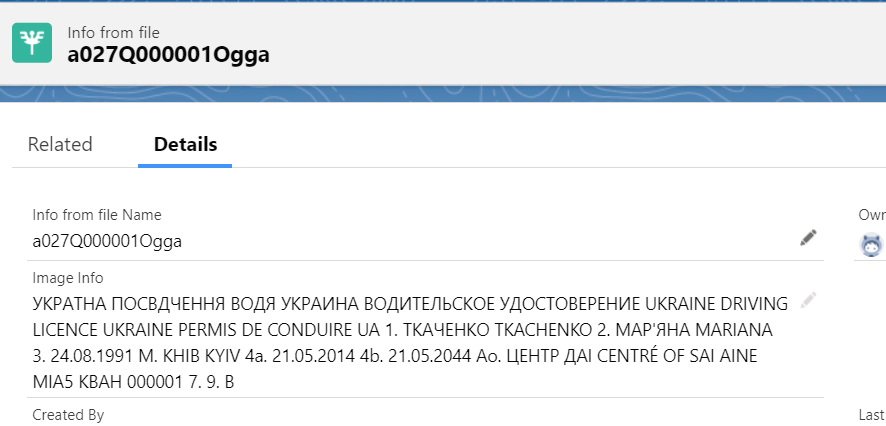
Несмотря на низкое качество фото и наличие посторонних «шумов” в виде водяных знаков — результат распознавания тоже довольно неплох.
Далее, полученную информацию можем использовать на свое усмотрение. Заполнять ею какие-то поля, формы или использовать для каких-либо других задач. Опытным путем установил, что английский текст распознается с большей точностью. Чем некачественнее фото — тем, естественно, хуже точность распознавания. Но в целом сервис довольно интересный и заслуживает внимания.
Спасибо.